
In my graduate data visualization course, I decided to teach my students about text analysis and the social web by working with them on code to scrape music reviews and then to use a machine learning algorithm to classify the reviews by genre (rock, jazz, hip-hop, folk). We started by identifying features that might distinguish the categories and created code to count the prevalence of those features.
In our model, we ended up using six features: the frequencies of keywords for each category, the average word length, and lexical diversity, which is defined as the size of the vocabulary of a review relative to the size of the review. (A review in which every word is used only once would have a lexical diversity score of 1. <- That sentence has a lexical diversity score of 17/18, 0.94.)
As you can see in the graph, with the first two discriminant functions, there isn’t a lot of separation between the genres. Jazz reviews and hip-hop reviews are most different from each other. Rock and folk reviews look a lot alike to the algorithm.
This is a tough classification task, at least based on countable qualities of the reviews. The next time I teach the course, we’re going to learn to do machine learning with sentiment analysis in addition to this one. I suspect that training the algorithm will be easier with the probabilities of occurrence of particular words in each type.

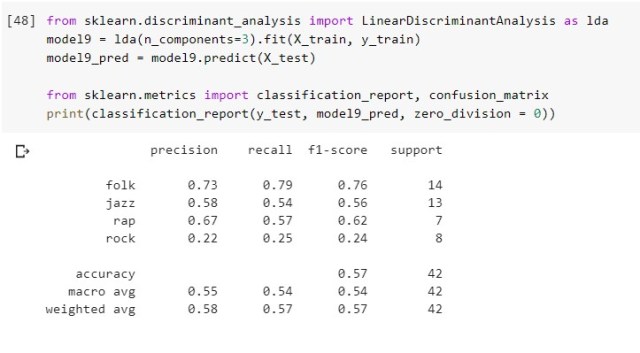
The algorithm, in this case a set of three linear discriminant functions, was able to correctly predict test cases most accurately for folk reviews and least accurately for rock reviews. (In the table above, precision is a ratio of the number of correct classifications, or true positives, to the true positives plus the false positives. Recall is the ratio of true positives to the sum of true positives and false negatives. These are two different metrics by which to judge the accuracy of classification. The f1 score is a weighted average of precision and recall.)
In order to see which features best classified each genre, we ran a series of logistic regression models to compare each genre against all of the others. In the two tables below, you can see the models for jazz/others and hip-hop/others. The coefficients indicate the change in the log odds of being in that category for a one unit change on the predictor.
Lexical diversity is inversely related to the odds of being classified as a jazz review. Reviews with larger vocabularies are less likely to be about jazz. Reviews that used bigger words were substantially more likely to be about jazz. For hip-hop, these relationships were reversed; hip-hop reviews used larger vocabularies but smaller words.


The full Python notebook that performed the analysis is available here: https://colab.research.google.com/drive/1ChvenFc80B6ZqcLOp3dDtsbcszXSTthY?usp=sharing